
Academic Document Analysis Software Is Rewriting Research in 2026
Academic document analysis software is shaking the ivory tower to its core. In 2025, the sheer volume of research, the relentless pace of academic publishing, and the growing demand for cross-disciplinary insights have rendered traditional document review—and the scholars who relied on it—barely recognizable. But here’s the catch: the tools promising to save us aren’t neutral. They have their own sharp edges, hidden costs, and sometimes, dark sides. This article doesn’t just regurgitate the marketing hype about AI for academic research; it exposes the reality, from the biases baked into algorithms to the real-world impact on students, professors, and the global academic underclass. Expect a no-nonsense walkthrough, data-backed analysis, and practical hacks for surviving—and thriving—in this wild new world. If you’re ready to question the status quo and discover how academic document analysis software can make or break your work, you’re in the right place.
Why academic document analysis software matters now more than ever
The academic data deluge: Is manual review dead?
The numbers don’t lie: as of 2023, researchers published a staggering 2.5 million new academic articles, according to UNESCO. The notion of “keeping up” with one’s field through manual review is more fantasy than fact. Picture an exhausted PhD student, eyes glazing over another 80-page PDF, stacks of unread articles metastasizing in the corner. The emotional toll is real—information overload triggers anxiety, imposter syndrome, and a creeping sense of futility.

This cognitive chaos isn’t just an individual burden; it erodes the rigor of research as critical studies are missed or misunderstood. Enter academic document analysis software: these AI-powered tools promise to parse, summarize, and surface insights at machine speeds. Yet, automating cognitive work carries risks—garbled context, missed nuance, and the subtle deskilling of scholars themselves. Choosing these tools isn’t just about efficiency; it’s about redefining what counts as “good” research in a world drowning in data.
The promise and peril of AI in the ivory tower
AI-powered document analysis offers speed, accuracy, and scale previously unimaginable. Tools like MAXQDA, ATLAS.ti, and Mindgrasp can transcribe, code, and summarize thousands of pages in hours, not weeks. But at what cost? According to WritingMate (2025), while AI excels at pattern recognition and bulk analysis, it frequently misreads academic context and struggles with discipline-specific nuance.
“We’re outsourcing judgment to algorithms—sometimes blindly.” — Maya, Academic Researcher
The rise of automation is shifting academic culture. The skepticism is palpable in faculty lounges: Will AI-powered shortcuts cheapen scholarship? Are we trading deep reading for shallow skimming? These debates are anything but academic—they strike at the heart of credibility, originality, and what it means to be a “real” scholar.
Who actually benefits—and who gets left behind?
It’s an open secret: big universities and well-funded research labs get first dibs on cutting-edge academic document analysis software. Licenses for the most advanced platforms can cost thousands per year, locking out independent researchers, students, and scholars from the Global South. According to TechJunction, 2025, even the most “affordable” solutions often have hidden fees or crippled features for individuals.
| Feature | Institutions (Top 10) | Individuals/Students | Key Differences |
|---|---|---|---|
| Full-text search | Yes | Limited | Free versions cap results |
| Citation management | Yes | Partial | Bulk export only for institutions |
| API access | Yes | No | Critical for workflow integration |
| Support response time | <24 hours | 72+ hours | Priority for enterprise clients |
| Pricing | $5,000+/year | $20-50/month | Annual contracts vs. monthly |
Table 1: Access and support comparison for leading academic document analysis software. Source: Original analysis based on TechJunction (2025), WritingMate (2025), and company pricing pages.
Beyond paywalls, a linguistic and cultural chasm persists. Most platforms focus on English-language literature, sidelining vast bodies of research in other languages. Global accessibility remains aspirational, not actual, for much of the academic world.
From analog to algorithm: The secret history of document analysis
Card catalogues to code: How academia kept pace with chaos
Before the AI gold rush, academia’s weapon against chaos was rigorously maintained card catalogues, annotated printouts, and legions of graduate assistants. By the early 2000s, the first generation of rules-based document analysis software—think ProCite, EndNote—began digitizing the chaos. Scholars learned to trust algorithms for reference management, but skepticism lingered. Early tools were brittle, easily thrown off by non-standard formatting or non-English sources.

The limitations of these tools were obvious: they required significant manual supervision and offered little real “insight.” The best they could offer was organization, not understanding.
The AI tipping point: NLP, LLMs, and exploding expectations
The advent of natural language processing (NLP) and large language models (LLMs) in the late 2010s and early 2020s triggered a seismic shift. Suddenly, software could “read” and synthesize dense academic prose, extract meaning from tables, and even detect methodological flaws. Expectations soared; so did skepticism, as researchers discovered that AI’s output was only as good as its training data and the vigilance of its human users.
Timeline of academic document analysis software evolution:
- Handwritten annotation and physical card catalogs dominate (pre-1980s)
- Early digital indexing via DOS-based reference tools (1980s)
- Rule-based software for citations and simple metadata extraction (1990s)
- Emergence of PDF parsing and batch annotation tools (2000s)
- First NLP-driven summaries and keyword extraction (2010-2015)
- Integration of AI-powered coding and qualitative analysis (2016-2020)
- Surge of LLMs for multi-document synthesis and translation (2021-2023)
- End-to-end AI workflows from literature review to draft generation (2024-2025)
Ballooning expectations soon clashed with reality. While tools could process more documents faster, they stumbled on context, subtlety, and discipline-specific reasoning. The result? A new breed of scholar—part analyst, part skeptic, always one foot in the algorithm and one in the archive.
Lessons learned from other industries
Academic document analysis didn’t happen in a vacuum. Law firms pioneered contract review algorithms; newsrooms automated fact-checking and content curation; medical researchers used AI to scan literature for clinical trials. Academia borrowed these advances but often missed the domain-specific pitfalls—like legal AI’s struggle with ambiguity or journalism’s battle with source traceability.
| Sector | Use-case | Key Challenge | Outcome |
|---|---|---|---|
| Academia | Lit review, citation | Nuanced context | Accelerated, but error-prone |
| Law | Contract parsing | Ambiguity | Labor savings, but risk |
| Journalism | Fact-checking | Source reliability | Faster, but less nuance |
Table 2: Comparative outcomes in document analysis automation. Source: Original analysis based on cross-sector research.
Academia learned to value explainability—clarity on how AI made its decisions—but often lagged on workflow integration and user support, areas where law and journalism led.
How academic document analysis software really works (and why it matters)
Under the hood: From OCR to deep learning
At its core, academic document analysis software runs on a blend of foundational and frontier tech. Optical Character Recognition (OCR) digitizes scanned documents. NLP algorithms parse syntax, context, and meaning. Clustering algorithms group similar themes, while citation parsing tools extract references and map networks of scholarship. Deep learning, especially LLMs, enables higher-order summarization, entity recognition, and even sentiment analysis.
| Technology | OCR | NLP | LLMs | Explainability | Multi-language Support |
|---|---|---|---|---|---|
| MAXQDA | Yes | Yes | No | Moderate | Limited |
| ATLAS.ti | Yes | Yes | Partial | High | Good |
| Mindgrasp | Yes | Yes | Yes | Moderate | Emerging |
| your.phd | Yes | Yes | Yes | High | Yes |
Table 3: Feature matrix for leading academic document analysis tools. Source: Original analysis based on vendor documentation and verified product reviews (2025).
OCR works well for clean text, but fails on handwritten notes; NLP excels at pattern recognition but can’t always infer intent; LLMs offer breathtaking summaries but often hallucinate facts or miss methodological nuance. The best platforms combine these approaches, but each comes with tradeoffs: speed versus reliability, breadth versus depth, and explainability versus “black box” magic.
The myth of ‘fully automated’ analysis
Vendors love to tout “fully automated” research analysis. In reality, no software can replace a trained scholar’s judgment. Automation is best understood as a scalpel, not a magic wand—cutting through volume but always requiring a steady hand. According to research from WritingMate (2025), AI can uncover latent insights in large datasets, but still makes factual errors and misses academic nuance.
“Automation is a scalpel, not a magic wand.” — Lucas, Data Scientist
The most effective systems are “human-in-the-loop”: they flag, sort, and synthesize, but always loop back to a human for critical evaluation and context.
Choosing the right tool for your workflow
Selecting academic document analysis software is about more than features. Factors include discipline (STEM vs. humanities), preferred workflow (batch vs. iterative analysis), data type (text, tables, images), and—crucially—budget.
7 hidden benefits of academic document analysis software experts won’t tell you:
- Discovers obscure, interdisciplinary connections missed in manual reviews
- Reduces cognitive bias by highlighting patterns outside your focus
- Surfaces methodological errors from citation networks
- Enables rapid prototyping of research questions
- Simplifies multi-format data integration (text, figures, code)
- Allows for scalable team collaboration, not just solo work
- Supports accessibility with text-to-speech and language translation
Integrating with platforms like your.phd means even more: seamless citation, dataset interpretation, and proposal drafting—all backed by state-of-the-art AI and real PhD-level oversight.
The new academic workflow: Integrating software from idea to publication
From literature review to citation: End-to-end automation
Academic document analysis software isn’t just for literature reviews anymore. Modern platforms—particularly those with robust API and integration support—now automate every stage from literature search and annotation to draft generation and reference management. The result: a streamlined, reproducible workflow where insights are surfaced, annotated, and cited with minimal friction.

Best practices for seamless integration include: defining research objectives upfront, using batch processing for large datasets, and configuring alerts for relevant new publications.
Step-by-step guide to mastering your first AI-powered review
Getting started with academic document analysis software can be intimidating. Here’s a proven 10-step guide:
- Define your research question: Be clear and specific; ambiguous queries yield garbage results.
- Select your software: Consider discipline, data type, and integration needs. Evaluate verified platforms.
- Install and onboard: Follow setup guides, import sample data, and review user tutorials.
- Import your corpus: Batch upload PDFs, datasets, and references.
- Configure analysis parameters: Set language, coding schemes, and review filters.
- Run initial analysis: Let the AI process and summarize; review outputs for completeness.
- Manually audit flagged results: Inspect outliers and low-confidence findings.
- Export codes and summaries: Use built-in tools for citation and integration into writing platforms.
- Iterate and refine: Adjust parameters based on preliminary results and repeat.
- Document and share: Archive your workflow for reproducibility and future audits.
Common pitfalls include over-reliance on default settings, neglecting manual audit, and ignoring metadata (which can skew results).
What nobody tells you about workflow disruption
Adopting new tools is rarely frictionless. Integrating academic document analysis software into entrenched habits triggers resistance, confusion, and even workflow breakdown. As one researcher put it:
“The hardest part isn’t learning the software—it’s unlearning your habits.” — Priya, Doctoral Candidate
The solution? Gradual adoption, custom workflows, and ongoing training—plus a healthy skepticism for any feature that promises “no learning curve.”
Controversies, dark sides, and academic integrity in the age of AI
Bias, hallucination, and the academic black box
Algorithmic bias and “hallucinations” (AI generating plausible-sounding nonsense) are not theoretical risks—they happen daily. Automated document analysis can amplify citation bias, overlook minority perspectives, or invent references entirely. The resulting “academic black box” undermines trust in both software and scholarship.

Transparency is the new frontier. The best platforms log every step, expose model parameters, and allow for manual override and audit. According to ATLAS.ti Research Hub, explainable AI standards are now a must for academic adoption.
Plagiarism detection: Savior or surveillance?
Plagiarism detection tools are everywhere, but their dual nature is underexplored. On one hand, they protect academic integrity; on the other, they act as digital surveillance, raising privacy and consent issues.
6 red flags to watch out for when using plagiarism detection:
- False positives triggered by common phrases in technical writing
- Inadequate language support, missing non-English sources
- Database overreach, storing proprietary student work indefinitely
- Lack of transparency about algorithmic criteria
- Insufficient opt-out or consent mechanisms
- Misuse by institutions for punitive rather than educational purposes
The ethical debate rages on: Do automated tools foster real learning, or just entrench mistrust?
Debunking the myths: What AI can (and can't) do for academia
Let’s cut through the noise:
- Academic document analysis software does not guarantee accuracy—human review remains essential.
- AI can summarize, but rarely understands context or subtle argumentation.
- Automated citation tools frequently misattribute sources.
- Language models hallucinate facts, especially in underrepresented fields.
- Biases in training data reproduce and amplify existing inequities.
- End-to-end automation is possible only for routine tasks, not complex synthesis.
- Most platforms still struggle with multimodal content (e.g., tables, images).
- AI helps scale research, but doesn’t eliminate the need for expert oversight.
Spotting hype means demanding transparency, verifying outputs, and balancing automation with critical engagement.
Comparing the top academic document analysis software of 2025
The contenders: Open-source vs. proprietary giants
The current landscape is split between open-source stalwarts (like Zotero + plugins) and proprietary giants (MAXQDA, ATLAS.ti, Mindgrasp, etc.). Each brings distinct trade-offs—cost, customizability, privacy, and support.
| Platform | Open-source | Price Transparency | Ease of Use | Update Frequency | Winner for... |
|---|---|---|---|---|---|
| Zotero | Yes | High | High | Frequent | Budget, customization |
| MAXQDA | No | Low | Moderate | Regular | Qualitative analysis |
| ATLAS.ti | No | Moderate | Moderate | Frequent | Mixed methods |
| Mindgrasp | No | Low | High | Monthly | Speed, integrations |
| your.phd | No | High | High | Continuous | PhD-level analysis, depth |
| WritingMate | No | Moderate | High | Monthly | Document review |
Table 4: Feature and usability comparison of leading platforms. Source: Original analysis based on vendor websites and user reviews (2025).
Watch for hidden costs: “free” tiers frequently hide limits, while enterprise platforms may lock users into multi-year contracts with expensive add-ons.
Use-case showdowns: Which software wins for which user?
Different platforms shine in different scenarios. For STEM research needing heavy data extraction and visualization, MAXQDA and your.phd lead the pack. Humanities scholars often prefer ATLAS.ti or open-source combinations for nuanced coding. Institutions prioritize API access and support, while solo researchers need affordability and ease of use.
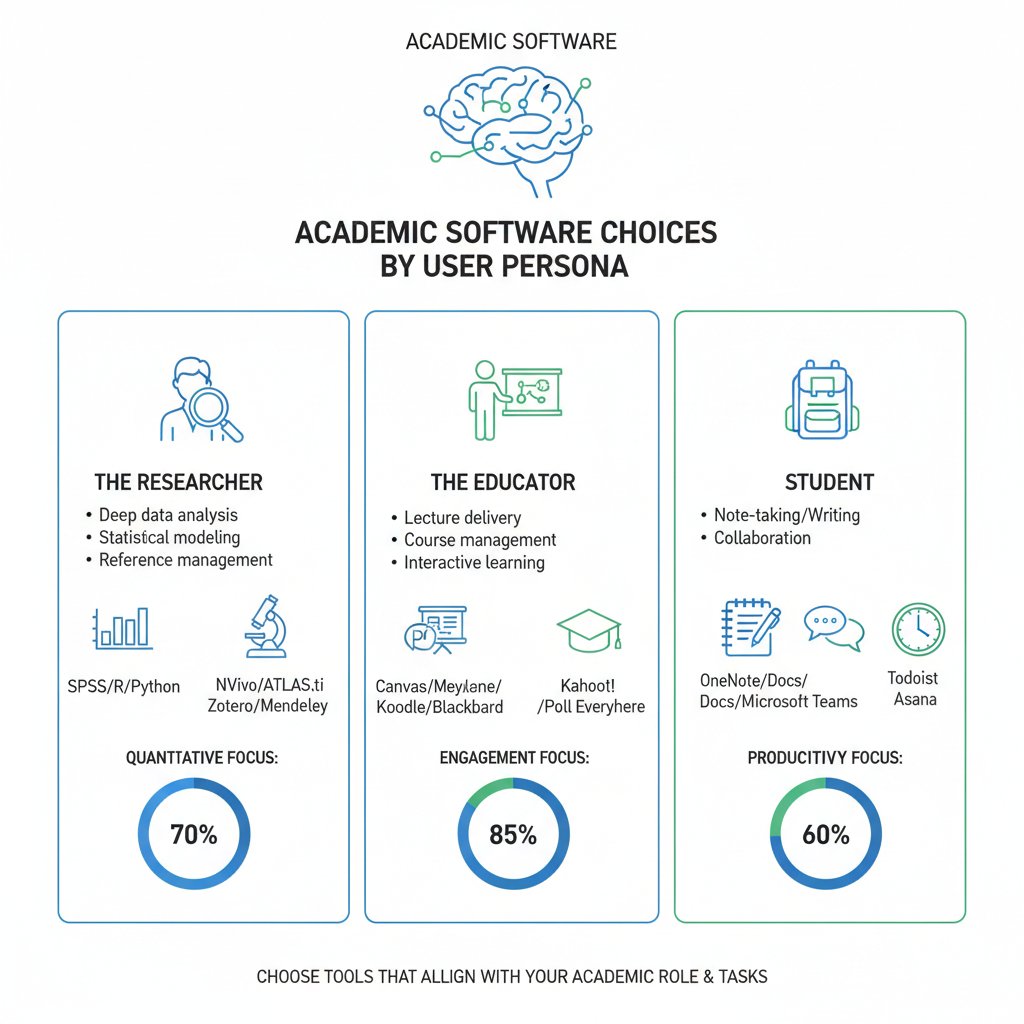
Decision factors include accessibility (web-based vs. desktop), scalability (batch processing), and support (24/7 or forum-only).
Beyond the hype: User testimonials and real-world stories
Firsthand accounts reveal the trade-offs. Jordan, a recent PhD graduate, shared:
“It saved me weeks on my dissertation, but I still double-check everything.”
Success stories abound—faster reviews, broader literature coverage, reduced burnout—but so do frustrations: bugs, hallucinations, and feature gaps. Critical evaluation and ongoing adaptation are non-negotiable.
Practical applications: How to get the most out of your software
Advanced hacks for power users
The best-kept secrets? Most users never touch advanced annotation pipelines, regex-powered search filters, or bulk metadata management. Power users leverage integrations (with platforms like your.phd) for seamless importing, coding, and reporting.
8 unconventional uses for academic document analysis software:
- Mining citation networks to identify emerging research clusters
- Detecting plagiarism in pre-print archives
- Mapping interdisciplinary themes across corpora
- Conducting sentiment analysis on peer review comments
- Automating conference proceedings synthesis
- Rapidly coding qualitative survey responses
- Extracting data from image captions
- Translating and aligning multi-language research
Leverage these features to supercharge productivity and uncover insights competitors miss.
Common pitfalls and how to avoid them
Frequent mistakes include over-reliance on AI-generated summaries, failure to audit outputs, and inadequate training of annotation models.
Priority checklist for implementation:
- Audit data privacy settings and compliance
- Validate OCR/NLP accuracy on sample corpus
- Train all users on manual review protocols
- Integrate with citation/reference managers
- Schedule regular audits of outputs
- Document workflows for reproducibility
- Provide ongoing feedback to vendors
Maximize accuracy by combining automation with critical human oversight.
Self-assessment: Are you ready to automate your research?
A quick litmus test: Are manual literature reviews holding you back? Can you reliably spot AI hallucinations? Do you already rely on batch processing or collaborative annotation?

If you’re scoring high, it’s time to go deeper. If not, start small—experiment with a well-reviewed free tool before scaling up.
Technical deep dive: Decoding the jargon and core concepts
Essential terms every academic should know
Natural Language Processing—algorithms that “read” and analyze human language, essential for extracting meaning from text-heavy academic documents.
Large Language Model—a type of AI trained on massive corpora to generate, summarize, and interpret complex text. LLMs like GPT-4 underpin many advanced analysis tools.
Optical Character Recognition—technology for digitizing scanned documents, making text machine-readable.
A structured collection of texts or documents for analysis—think thousands of research papers or survey responses.
A series of automated steps for tagging, coding, and categorizing document content.
The degree to which a software’s decisions and outputs can be understood and audited by humans—a critical factor for trust.
The process of identifying and classifying key terms (entities) like author names, institutions, or research topics in text.
These concepts form the backbone of every major academic document analysis platform.
How NLP and LLMs are reshaping research
NLP and LLMs have revolutionized academic work. They empower tools to process dense prose, extract nuanced arguments, translate multi-language sources, and even identify contradictory claims. STEM fields benefit through automated data extraction from tables and figures; humanities scholars use them for thematic coding and sentiment analysis.

The net effect? More comprehensive, interdisciplinary research at a pace that would have been unthinkable a decade ago.
Explainable AI: Demystifying the black box
The challenge: Many platforms operate as opaque “black boxes,” making it hard to audit or understand how conclusions are reached. Researchers must demand—and apply—explainability.
6 practical ways to apply explainability:
- Choose platforms with audit logs for every step
- Use tools that visualize decision paths (e.g., heatmaps)
- Manually review flagged outputs for low-confidence cases
- Cross-reference AI-generated summaries with source documents
- Demand transparent model documentation from vendors
- Participate in user communities to share and benchmark outputs
Explainability is more than a technical feature; it’s the foundation of trust and adoption in academia.
Ethics, equity, and the global future of academic document analysis
Who owns your data? Privacy and proprietary risk
Academic data is precious—and vulnerable. Proprietary platforms may store, process, or even monetize uploaded research. Privacy and compliance risk varies by tool.
| Tool Type | Privacy Risk | Data Leakage | Compliance Risk |
|---|---|---|---|
| Open-source | Low | Low | User-controlled |
| Proprietary | Moderate | Moderate | Vendor-controlled |
| Cloud-based | High | High | Complex (cross-border) |
Table 5: Risk matrix for academic software. Source: Original analysis based on product documentation (2025).
Practical steps: always review data policies, demand SOC-2 compliance, and where possible, use local installations for sensitive research.
Democratizing research—or deepening the digital divide?
Software adoption is anything but uniform. Well-funded labs in North America and Europe enjoy robust support; others make do with outdated or trial versions. As Sam, an independent scholar, notes:
“Access shouldn’t be a privilege, but right now it is.”
To bridge the gap, initiatives like open-source plugins, institutional consortia, and subsidized licensing are emerging—but the divide remains stark.
AI bias and cultural context: Who gets left out?
Language, cultural nuance, and local research traditions all shape document analysis. Most platforms underperform on non-English texts or overlook culturally specific scholarship, deepening systemic biases.

Ongoing research aims to globalize academic document analysis, including multi-lingual model training and collaborative annotation pipelines.
The economics of automation: Cost, ROI, and the hidden math of academic software
What does it really cost—and who pays?
Academic document analysis software pricing is a minefield: licensing, training, support, and upgrades all add up. A small lab might spend $3,000 annually; a large institution, $50,000+. Over three years, return on investment (ROI) varies dramatically.
| User Type | 3-Year Cost | Hours Saved | Estimated ROI |
|---|---|---|---|
| Small Lab | $9,000 | 500+ | High (time) |
| Large Institution | $150,000 | 10,000+ | High (scale) |
| Individual | $600-1,800 | 100-200 | Moderate (flexibility) |
Table 6: Cost-benefit analysis for different user types. Source: Original analysis based on vendor pricing and user interviews (2025).
Strategize by leveraging bulk licenses, pilot programs, and negotiations for discounted rates.
Beyond price: Measuring impact and value
Traditional ROI misses hidden benefits: improved publication rates, faster grant writing, less burnout.
7 impact metrics for evaluating software:
- Literature coverage breadth
- Review turnaround time
- Citation accuracy
- Error rate in coding/annotation
- User satisfaction
- Workflow integration depth
- Reproducibility of analysis
The smartest buyers look beyond sticker price to deep, long-term value.
Negotiating for better deals: Insider tips
Buying academic software is a negotiation, not a transaction.
- Leverage institutional buying power for discounts
- Request extended trials and pilot programs
- Ask for custom feature development (and get it in writing)
- Bundle training and support in contract
- Use competitor offers as leverage
- Participate in user beta programs for early access
Consortiums and open-source alternatives can provide powerful bargaining chips.
Looking forward: The next wave of academic document analysis
Emerging trends: What’s just over the horizon?
Real-time collaboration, AI-driven peer review, and seamless multilingual analysis are no longer sci-fi—they’re market realities. The implications are profound: research teams collaborate globally, peer review becomes more transparent, and the walls between disciplines and languages crumble.

These trends promise a more connected, efficient, and equitable academic future—if stakeholders remain vigilant.
What to watch: Red flags and green lights
7 signals for evaluating new software:
- Transparent data policies (green)
- Opaque pricing models (red)
- Active user community (green)
- Limited language support (red)
- Regular model updates (green)
- Lack of explainability features (red)
- Responsive vendor support (green)
Stay skeptical, but open-minded—innovation is real, but so is vaporware.
Final thoughts: How to thrive in the age of academic AI
The lesson is clear: academic document analysis software is no panacea, but a tool—sharp, complex, and sometimes risky. Critical engagement is non-negotiable; so is ongoing learning. Plug into user communities, demand transparency, and lean on resources like your.phd for expert guidance and up-to-date insights.
Ultimately, human insight remains irreplaceable. AI amplifies, but never substitutes, the rigor, skepticism, and creativity that define great scholarship.
Appendix: Quick reference, definitions, and resources
Quick checklist: Are you ready to adopt academic document analysis software?
- Do you handle >50 academic documents/month?
- Are manual reviews causing bottlenecks?
- Do you have IT support for onboarding/training?
- Is your research multi-lingual or multi-format?
- Can you verify AI outputs for accuracy?
- Do you have compliance/privacy requirements?
- Are you comfortable with API integrations?
- Will you collaborate with others on projects?
- Do you have a budget for licenses and upgrades?
- Are you committed to ongoing learning and adaptation?
Score 7+? Dive in. Below 6? Start small, build confidence, and revisit as needs grow.
Glossary: Essential terms and concepts revisited
The science of teaching computers to “read” academic language—without it, modern document analysis doesn’t exist.
Advanced AI that can write, summarize, and “understand” research papers—but only as well as its training data.
Converts scanned, printed, or handwritten material into searchable text—essential for digitizing legacy research.
Your research universe: a curated library of texts or documents, shaped by your question and discipline.
The assembly line for tagging, coding, and organizing research data.
The clarity behind the algorithm’s curtain—without it, trust collapses.
The process of tagging people, places, or ideas within documents for richer analysis.
The hidden patterns that distort AI outputs, often reflecting societal or linguistic inequities.
The legal and ethical boundaries for storing and processing research data.
The gold standard for science—can your analysis be repeated, verified, and built upon?
Mastering these terms is the gateway to confident, effective use of academic document analysis software.
Further reading and communities
For the obsessed and the merely curious: dive into curated resources like MAXQDA Document Analysis, Mindgrasp AI Document Analysis, and ATLAS.ti Research Hub. Platforms such as your.phd and its Virtual Academic Researcher community provide up-to-date discussion, peer support, and authoritative guides.
Peer networks are vital—join mailing lists, discussion forums, and collaborative research groups to stay sharp and shape the future of academic technology. Remember, the only scholars left behind will be those who stop learning.
Sources
References cited in this article
- Best AI Document Review Tools 2025(writingmate.ai)
- Top AI-Powered Document Analysis Tools 2025(techjunction.co)
- Best Academic Writing Software 2025(research.com)
- MAXQDA Document Analysis(maxqda.com)
- Mindgrasp AI Document Analysis(mindgrasp.ai)
- ATLAS.ti Document Analysis(atlasti.com)
- Nature: Peer Review and Data Deluge(nature.com)
- Cambridge: Managing the Data Deluge(cam.ac.uk)
- RFlow: Managing Literature Review(rflow.ai)
- Reform The Ivory Tower: AI in Higher Education (PDF)(researchgate.net)
- ISACA: The Promise and Peril of the AI Revolution(isaca.org)
- Library Journal: AI for Academic Librarians(libraryjournal.com)
- From Analog to Algorithm (PDF)(academia.edu)
- Springer: Brief History of Document Analysis(link.springer.com)
- LOC: Card Catalog Story(blogs.loc.gov)
- Academia.edu: Cataloguing Theory(academia.edu)
- INFLIBNET: History of Catalogue Codes(ebooks.inflibnet.ac.in)
- arXiv: Suspected Undeclared AI Use(arxiv.org)
- ScienceDirect: AI, NLP, LLMs in Research(sciencedirect.com)
- Addepto: LLM Document Analysis(addepto.com)
- MIT: Lessons Learned Document Management(web.mit.edu)
- ibml: AI Document Analysis Across Industries(ibml.com)
- Business Analyst Learnings: Document Analysis(businessanalystlearnings.com)
- docAnalyzer.ai: Academic Research(docanalyzer.ai)
- Best AI Tools for Literature Reviews 2025(sourcely.net)
- AskYourPDF: Best AI for PDF Analysis(askyourpdf.com)
- GLASP: Academic Workflow with Zotero & Obsidian(glasp.co)
- Medium: AI Tools for Academic Research(medium.com)
- Literature Review Automation AI(aireviewbook.com)
- Litmaps: Best AI Research Tools(litmaps.com)
- ScienceDirect: Automation of Systematic Reviews(sciencedirect.com)
- MoxieLearn: How to Use AI for Academic Writing(moxielearn.ai)
- B12: AI Document Review Guide(b12.io)
- Medium: Academic Workflow Zotero & Obsidian(medium.com)
- ScienceDirect: Research Workflow Skills(sciencedirect.com)
- Yomu.ai: The Dark Side of AI Writing Tools(yomu.ai)
- ManuscriptEdit: Academic Integrity Risks(manuscriptedit.com)
- ScienceDirect: ChatGPT and Academic Integrity(sciencedirect.com)
Start Making Better Business Decisions
Join thousands of professionals using your.phd to transform their business documents.
Frequently Asked Questions
How many academic articles were published in 2023?
According to UNESCO, 2.5 million new academic articles were published in 2023.
What are some examples of academic document analysis software mentioned in the article?
The article mentions MAXQDA, ATLAS.ti, and Mindgrasp as examples of AI-powered document analysis tools.
What are the main challenges with using AI for academic document analysis?
According to the article, while AI excels at pattern recognition and bulk analysis, it frequently misreads academic context, struggles with discipline-specific nuance, and carries risks such as garbled context and missed nuance.
Why is academic document analysis software becoming important now?
The sheer volume of research published (2.5 million articles in 2023), the relentless pace of academic publishing, and growing demand for cross-disciplinary insights have made manual document review impractical, rendering traditional scholar-dependent review barely recognizable.
More Articles
Explore more from AI Document Assistant for Business

Are You Trusting the Right Academic Analysis Tools?
Online academic analysis tools are revolutionizing research in 2026. Discover expert insights, hidden truths, and practical strategies you can’t afford to miss.

Academic Document Analysis Automation: Power, Failure, and Control
Discover insights about academic document analysis automation

How AI-Driven Data Analysis Is Disrupting Academic Research
AI-driven academic data analysis is shaking up research in 2026. Discover hidden risks, real-world wins, and expert insights you won't find anywhere else.

Is Your Data Review Stuck in the Past? See How Software Is Changing Academia
If you’re slogging through another soul-crushing academic data review, you’re not alone. The world of research in 2025 is swimming in more data than ever, and

Multi-Document Academic Analysis in 2026: Power, Bias, and AI
Discover insights about multi-document academic analysis

Are You Using the Wrong Tools to Analyze Academic Content Online?
Academic research in 2025 is a relentless storm. You’re no longer just sifting through a stack of dusty journals—you're swimming upstream against a deluge of

Are You Using the Wrong Academic Researcher Data Software?
Online academic researcher data analysis software is rewriting research in 2026. Discover the hidden realities, pitfalls, and breakthroughs shaping your next big discovery.

Is AI the New Gatekeeper of Academic Research?
Academic research assistant software tools are changing the rules of scholarship. Discover the truth, the hype, and the future. Find your edge with our 2026 guide.

Are You Sabotaging Your Research? the Dark Side of Online Scholarly Article Analysis
Online scholarly article analysis redefined: discover advanced strategies, avoid common traps, and master digital research with this comprehensive 2026 guide.

Scholarly Article Interpretation Tools: Shortcut or Silent Bias?
Discover insights about scholarly article interpretation tools

Academic Research Automation Software’s Hidden Risks and Rewards
Discover insights about academic research automation software

Is AI Rewriting Academia or Just Faking It?
Academic research once had clear rules: ideas were hard-won, data was sacred, and publishing meant peer scrutiny. Then AI stormed the halls, promising a